Tianren Ma马 天任Ph.D. CandidateLearning and Machine Perception Lab (LAMP) School of Electronic, Electrical and Communication Engineering University of Chinese Academy of Sciences (UCAS) Beijing, China, 100083. Email: matianren18##mails.ucas.ac.cn Github: https://github.com/martian422 |

|
My Biography
I am a Ph.D. candidate of LAMP at UCAS, advised by Prof. Qixiang Ye.
I got my B.E. degree in UCAS in 2022.
Currently, I'm exploring multimodal model's generation and reinforcement learning methods with discrete structures.
I'm also interested in photography, graphic design, and musicals.
个人简介
我是中国科学院大学LAMP实验室的博士研究生, 导师是叶齐祥教授。
2022年,我在中国科学院大学获得工学学士学位。
目前,我正在研究基于离散变量的多模态生成和强化学习办法。
我对摄影,平面设计以及音乐剧都很感兴趣。
Major Publications
主要论文
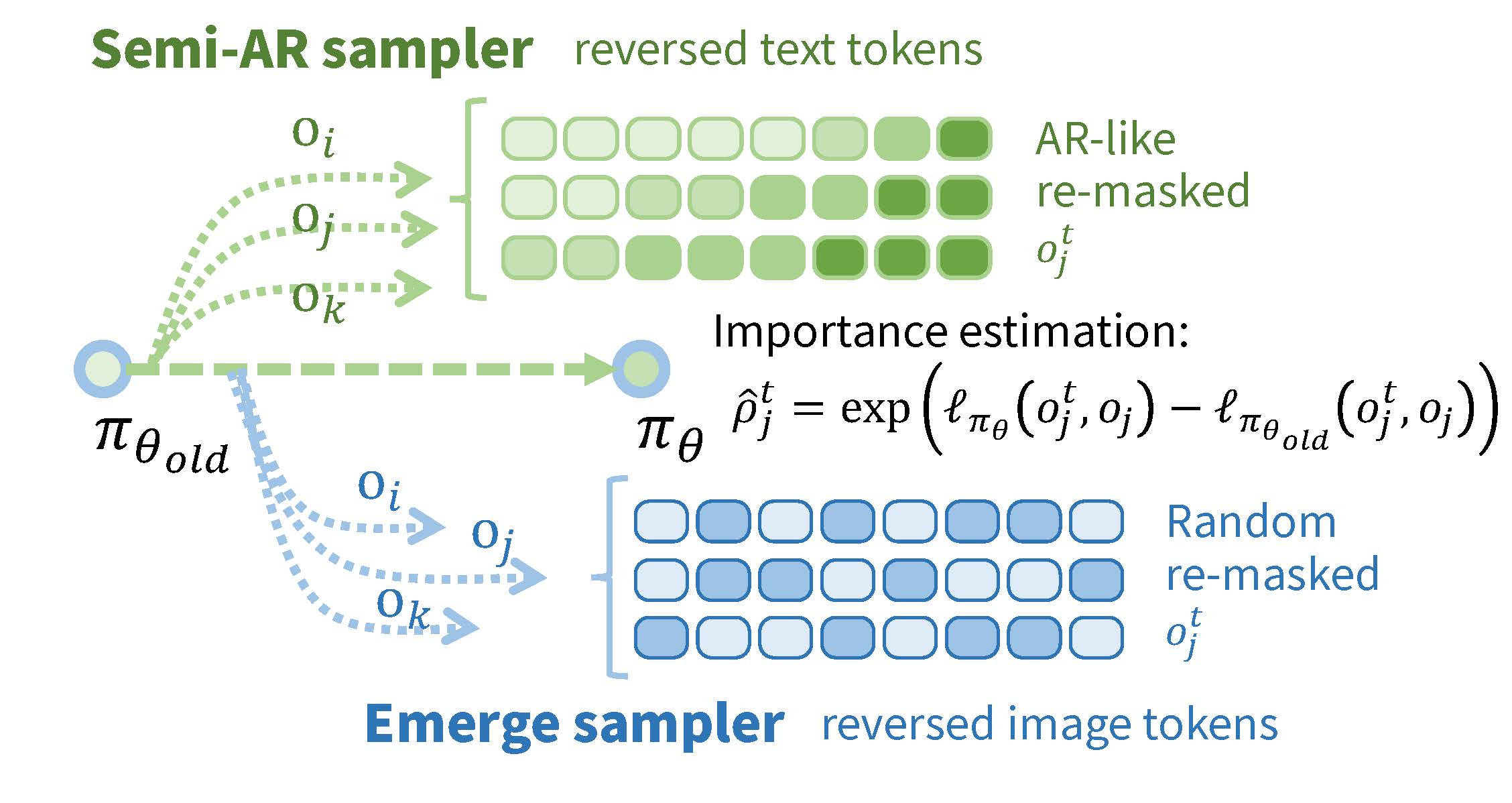 |
Tianren Ma, Mu Zhang, Yibing Wang, Qixiang Ye
Consolidating Reinforcement Learning For Multimodal Discrete Diffusion Models Accepted by ICLR 2026. [Paper] [Code] |
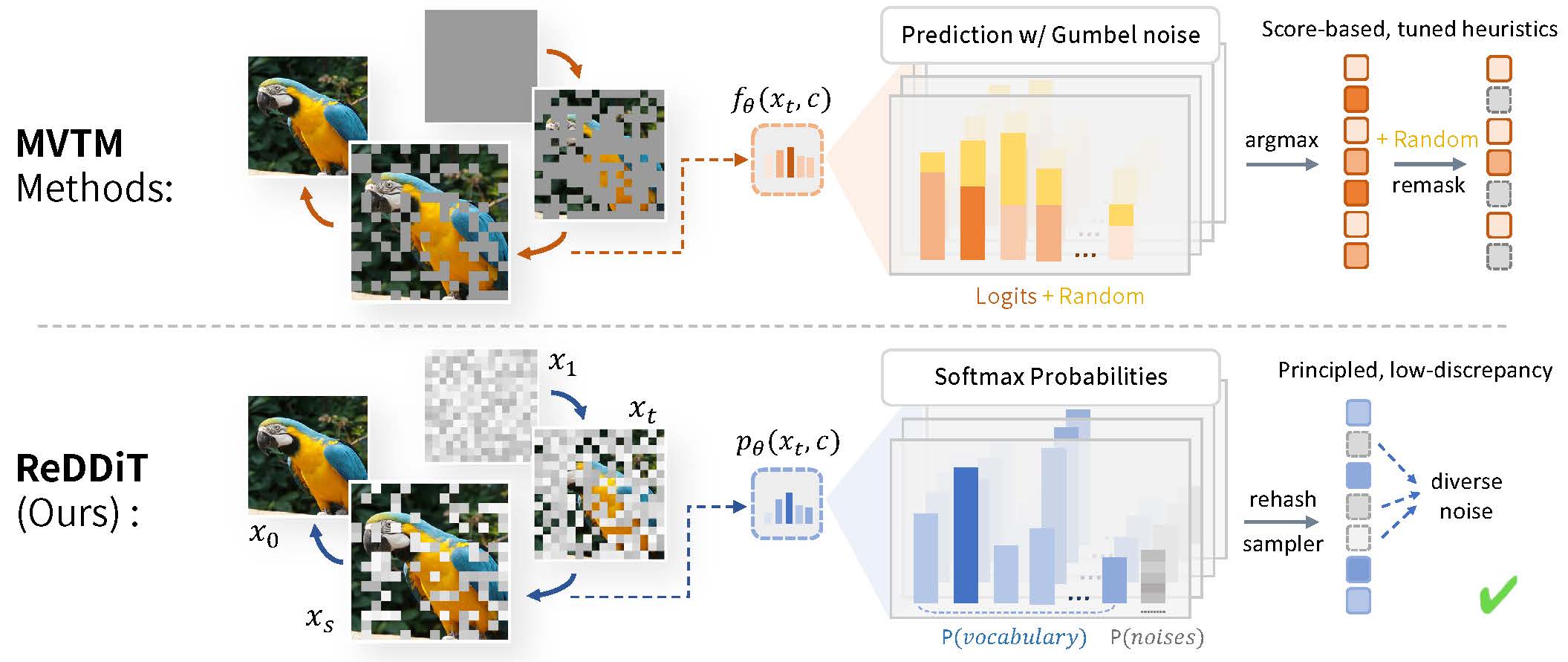 |
Tianren Ma, Xiaosong Zhang, Boyu Yang, Junlan Feng, Qixiang Ye
ReDDiT: Rehashing Noise for Discrete Visual Generation Accepted by ICLR 2026. [Paper] [Code] |
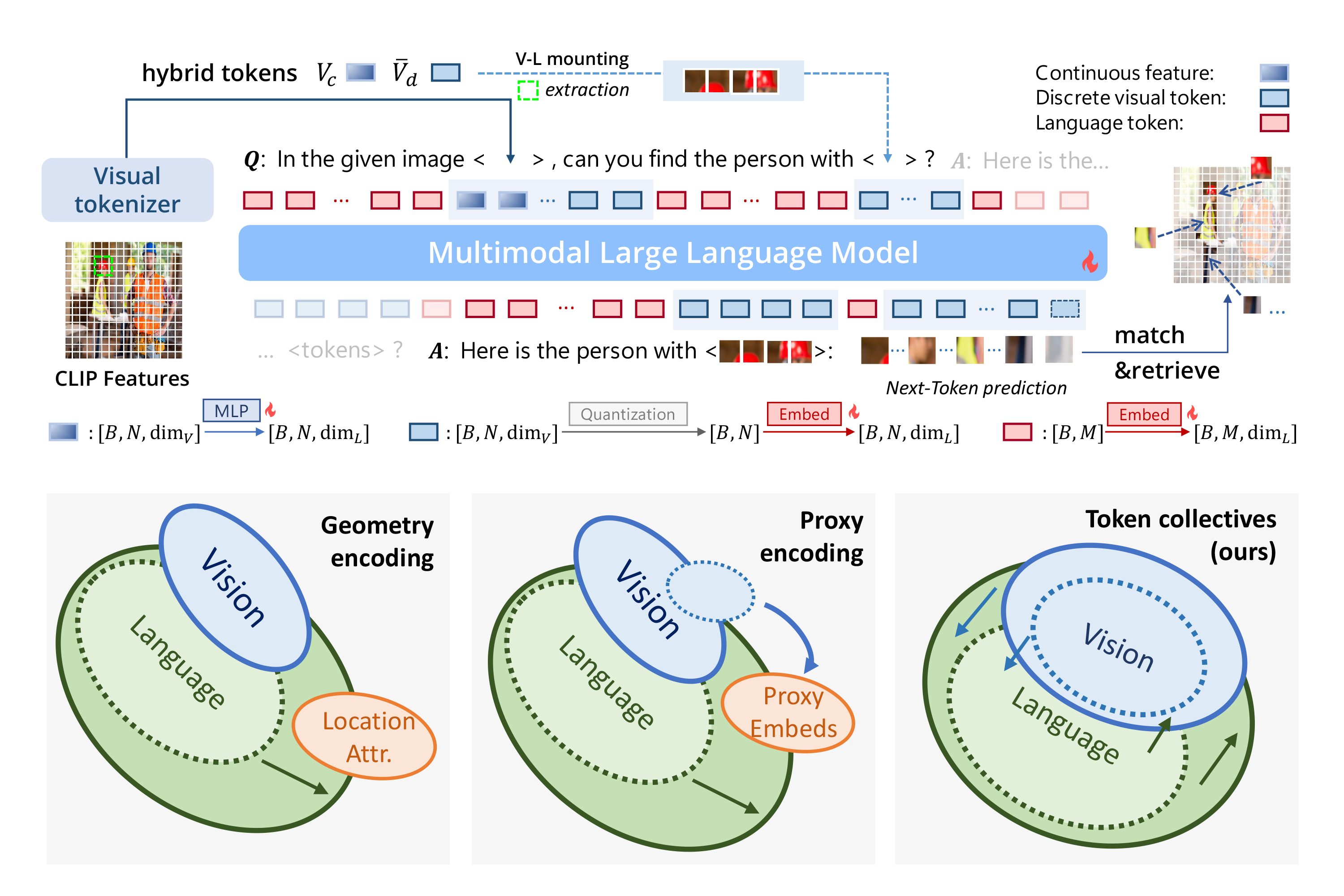 |
Tianren Ma, Lingxi Xie, Yunjie Tian, Boyu Yang, Qixiang Ye
ClawMachine: Learning to Fetch Visual Tokens for Referential Comprehension Accepted by ICLR 2025. [Paper] [Code] |
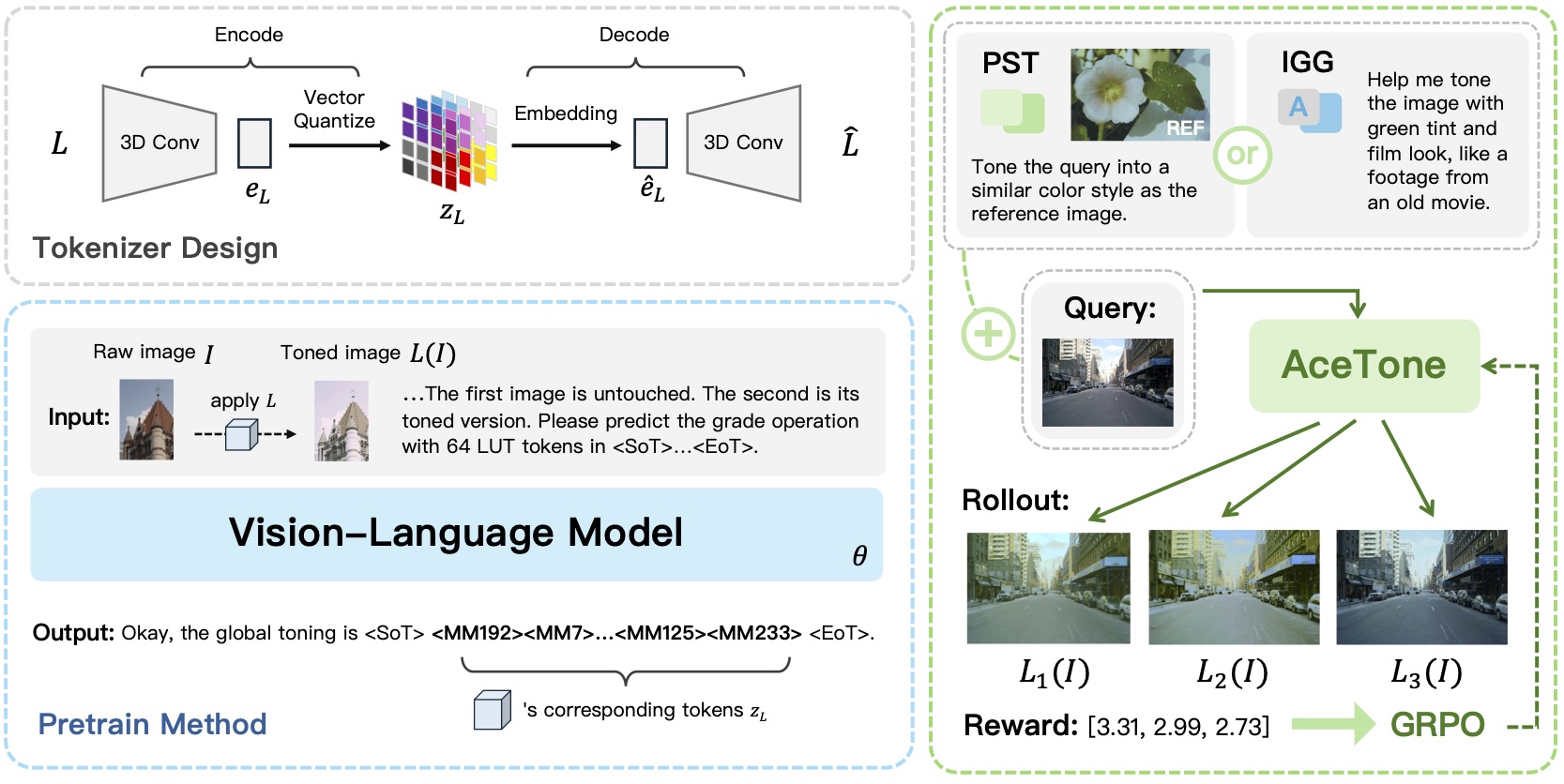 |
Tianren Ma, Mingxiang Liao, Xijin Zhang, Qixiang Ye
AceTone: Bridging Words and Colors for Conditional Image Grading Accepted by CVPR 2026. [Paper] [Code] |
 |
Mingxiang Liao*, Tianren Ma*, Xijin Zhang
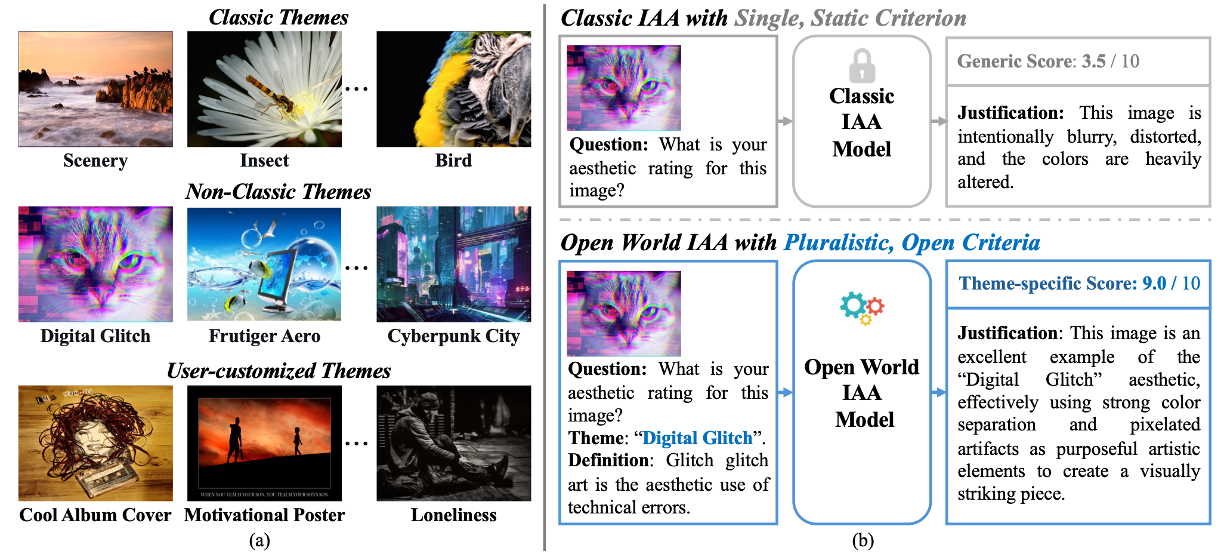
Open World Image Aesthetic Assessment Preprint. [Paper] [Code] |
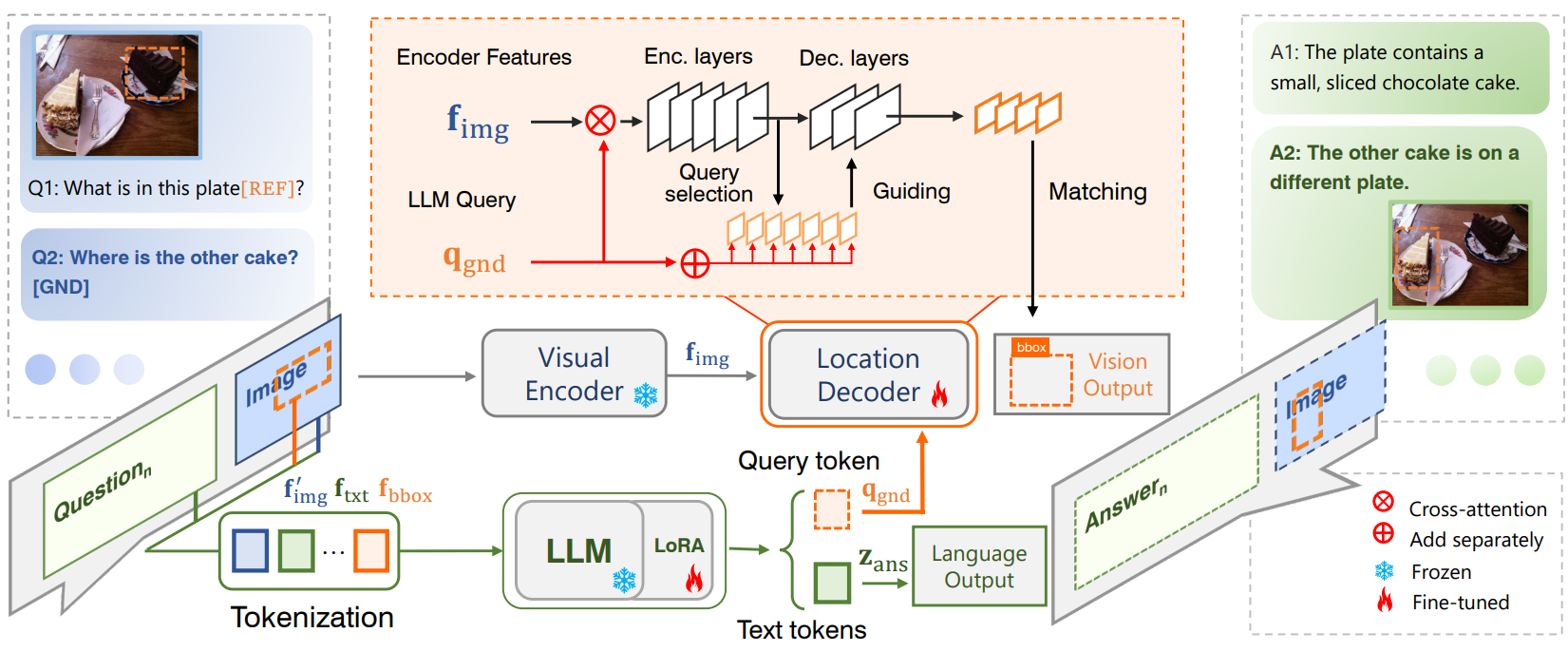 |
Yunjie Tian*, Tianren Ma*, Lingxi Xie, Qixiang Ye
ChatterBox: Multimodal Referring and Grounding with Chain-of-Questions Accepted by AAAI 2025. [Paper] [Code] |
Co-author Publications
其他论文
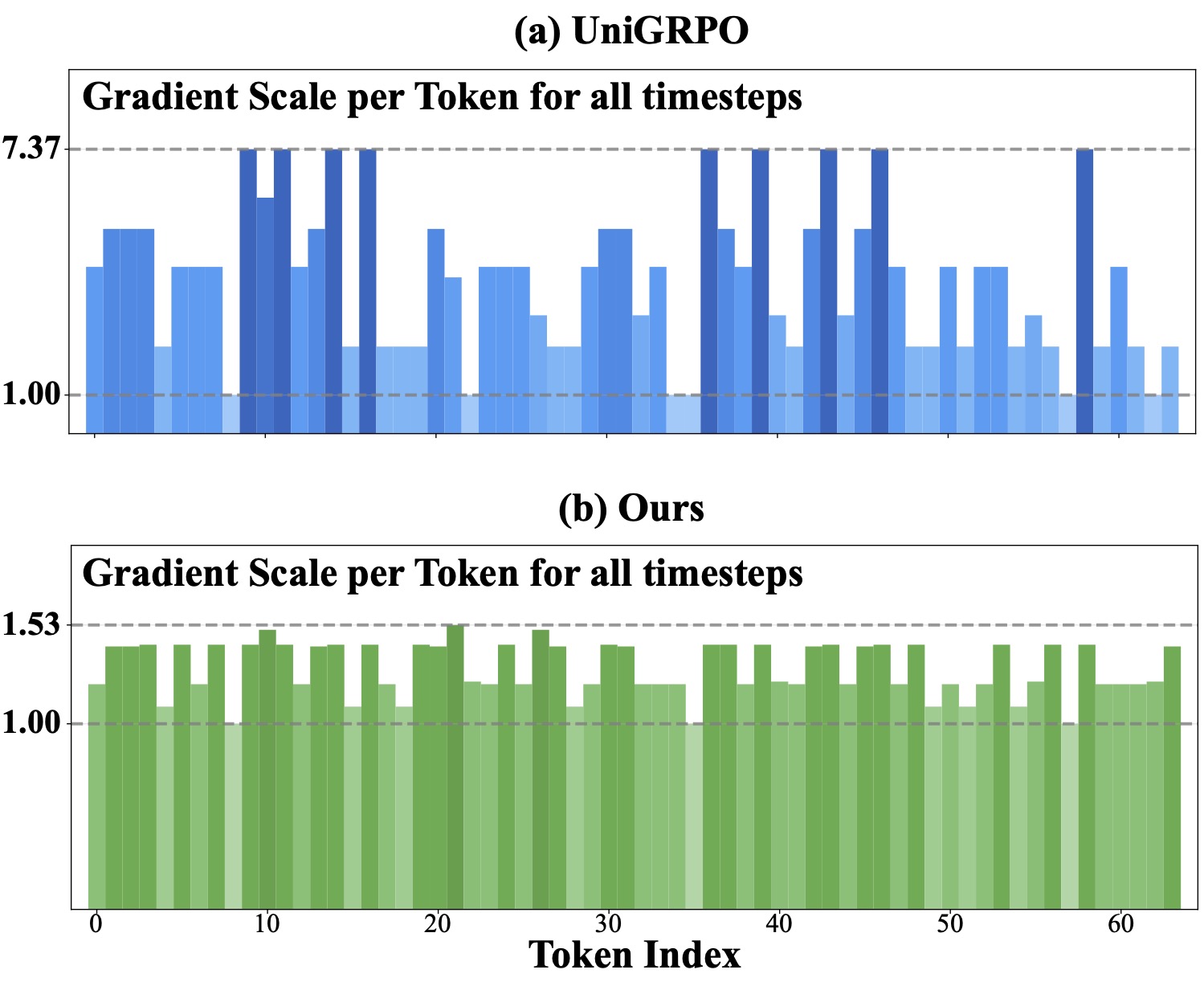 |
Mu Zhang, Tianren Ma, Yunfan Liu, Kun Hu, Qixiang Ye
RebRL: Reinforcing Discrete Visual Diffusion Models with Rebalanced Timestep Credits Accepted by CVPR 2026. [Paper] [Code] |
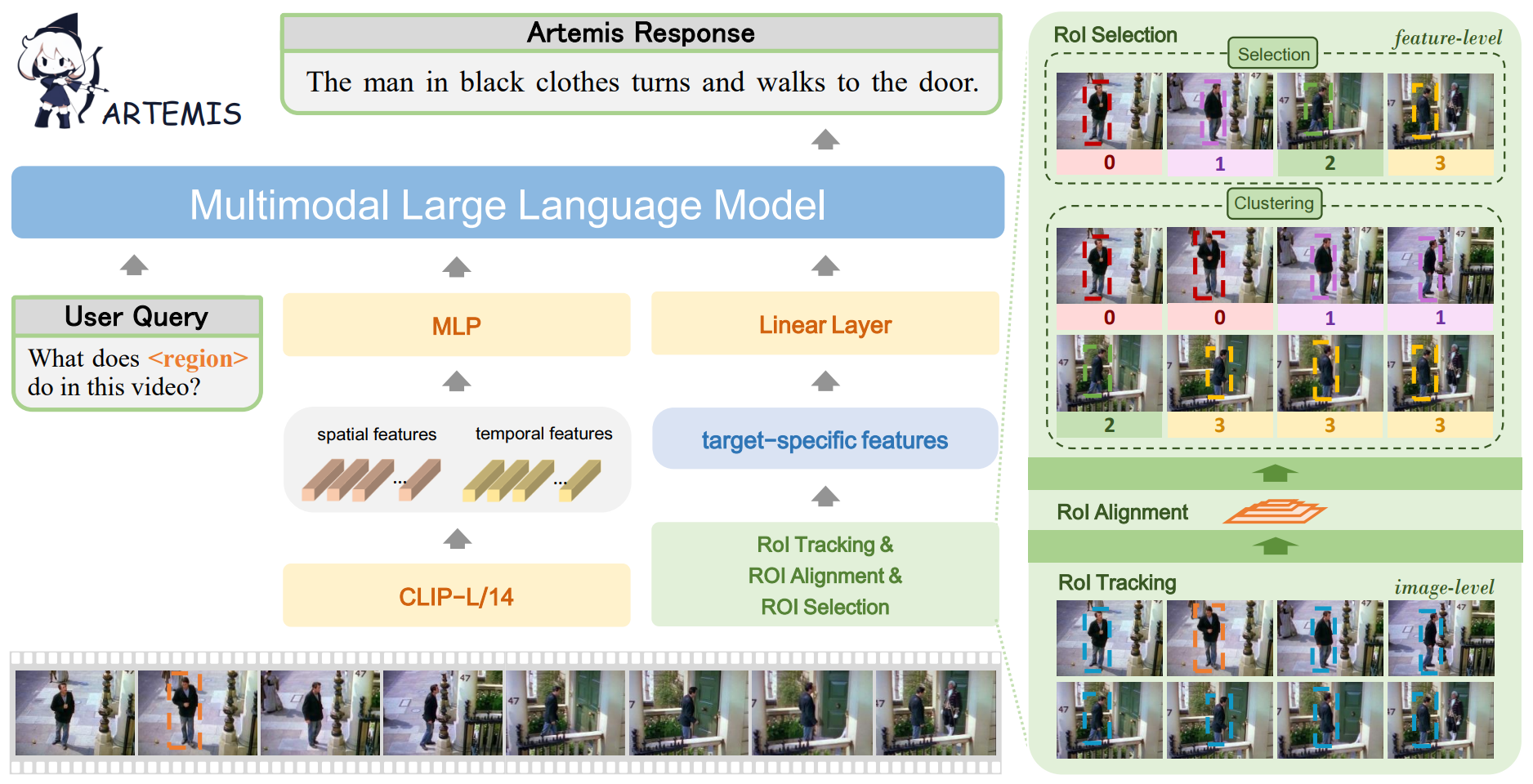 |
Jihao Qiu*, Yuan Zhang*, Xi Tang*, Lingxi Xie, Tianren Ma, Pengyu Yan, David Doermann, Qixiang Ye, Yunjie Tian
Artemis: Towards Referential Understanding in Complex Videos Accepted by NeurIPS 2024. [Paper] [Code] |
* indicates equal contribution.
* 表示作者贡献相同。